


出品 | 搜狐科技
作者 | 梁昌均
OpenAI、DeepSeeK点燃大模型推理浪潮后,越来越多的大模型企业开始涌入,阿里、百度、腾讯、字节、谷歌等先后发布推理模型。
不少企业都在想着如何憋大招,后发制人。这一次轮到估值超200亿元的独角兽MiniMax,发布首款推理模型M1,并称这是全球首款开源权重、大规模混合注意力推理模型。
根据基准评测,M1性能超越国内闭源模型,接近海外最领先模型,部分任务超过DeepSeek、阿里、字节,以及OpenAI、谷歌和Anthropic等最新最强的开闭源模型。
在年初DeepSeek-R1推出后,MiniMax所在的“AI六小龙”阵营被打蒙了。如今,M1一定程度上让MiniMax在国内模型阵营梯队中踏上一个台阶。
“第一次感觉到大山不是不能翻越。”MiniMax创始人&CEO闫俊杰发文表示。
搜狐科技了解到,M1是MiniMax此次为期5天的发布周的第一弹,后续还将官宣智能体应用,并在海螺AI视频、音乐等模型和产品层面带来更多更新。
多项任务性能赶超Deepseek,输入长度业内最高
M1是MiniMax推出的首款推理模型,其基于MiniMax-Text-01模型开发,总参数达4560亿,每token激活参数459亿,采用了混合专家(MoE)架构和线性注意力机制(Lightning Attention)。
MiniMax在业内主流的17个评测集上测试了M1,结果显示,其在部分数学和代码测试超过Anthropic最强模型Claude-4-Opus、字节最新发布的Seed-Thinking-v1.5,以及参数达6710亿的Deepseek-R1,但不及R1-0528版本,距o3和谷歌最新的Gemini 2.5-pro也有一定差距。
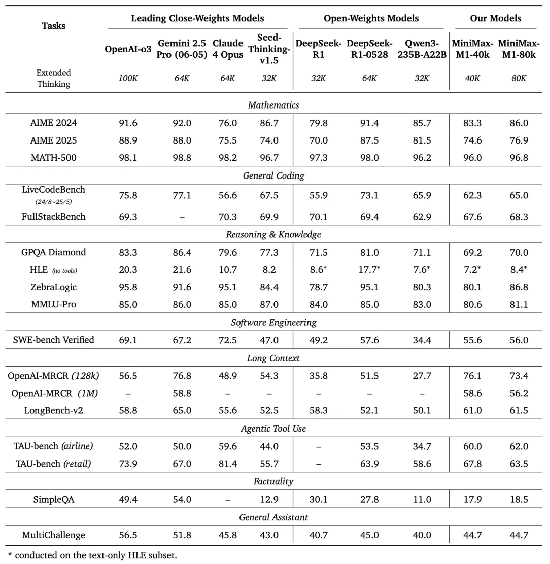
不过,M1在软件工程、长上下文、工具使用等复杂的生产力场景中,具备比较全面的优势。如M1在测试软件工程能力的SWE-bench上取得超过55%的成绩,虽不及海外顶尖模型,但显著高于国内的DeepSeek-R1、以及阿里和字节模型。
在长上下文理解任务中,M1则在三项基准测试上全面超越所有开源模型,并超越o3和Claude-4等闭源模型,仅以微弱差距落后于Gemini 2.5 Pro,全球排名第二。
在代理工具使用场景测试TAU-bench中,M1在airline(航空领域)的得分超过60%,领跑目前最为领先的开闭源模型;在retail(零售领域)的表现则超过DeepSeek、阿里、字节和谷歌模型,略逊于o3和Claude-4模型。
“通过全面的评估,MiniMax-M1与DeepSeek-R1和Qwen3-235B一起,跻身全球最佳开源权重模型之列。”MiniMax表示。
值得注意的是,M1包括两个版本模型,分别有40k和80k的思考上下文长度,其中M1-80k在多数基准测试中始终优于MiniMax-M1-40k,这充分验证了扩展测试时计算资源的有效性。

M1另一个显著优势是支持高达100万Token上下文输入,和Gemini 2.5 Pro一样,业内最高,这是DeepSeek-R1输入长度的8倍。同时,M1支持8万Token的推理输出,除o3外最高。
架构和算法创新,强化学习成本54万美元
这些性能得益于MiniMax在架构和算法的创新。
过去半年,推理模型借助大规模强化学习持续向上探索着大语言模型的天花板,但由于Transformer架构中,注意力机制的计算量会随序列长度呈平方级增长,导致其在推理扩展上面临挑战。
DeepSeek和月之暗面此前均针对注意力机制进行了研发,前者提出原生稀疏注意力(NSA),后者提出块注意力混合架构(MoBA),使得上下文处理速度提升十多倍。
MiniMax则在论文中提到,业内此前提出了稀疏注意力等方法解决,但尚未在大规模推理模型中得到充分验证,为此还需在高效扩展推理方面进行探索。
M1则在混合专家架构上采用了线性注意力机制(Lightning Attention),其核心是通过将注意力计算分解为多个小块,采用线性复杂度的计算方式,实现对长序列的高效处理。
“这种设计理论上能够高效地将推理长度扩展到数十万 token。”MiniMax表示,这还能带来计算成本的大幅下降,“这个特性使我们在训练和推理的时候都有很大的算力效率优势”。
例如,与DeepSeek-R1 相比,在生成长度为64K token时,M1消耗的算力FLOPs不到其50%;在长度为100K token时,消耗的FLOPs约为其25%。

这正是M1上下文长度得到扩展的关键,并使其特别适合需要处理长输入和进行深入思考的复杂、现实世界任务,因此其在软件工程、长上下文、工具使用等方面体现出性能优势。
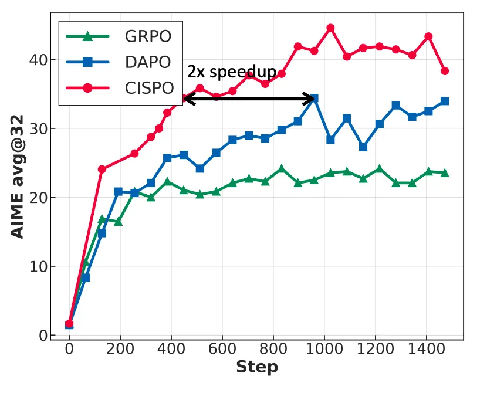
当然,这也离不开M1在进行大规模强化学习时的算法创新。论文提到两个关键创新,一是提出一种新颖的强化学习算法CISPO,从而提升强化学习效率。
经过验证对比,这种算法具备更高效率。如在数学测试基准AIME的实验中,MiniMax发现CISPO比字节近期提出的DAPO强化学习算法实现了两倍的加速,即其只需50%的训练步骤就可以与DAPO的表现相匹配,同时也显著优于DeepSeek此前使用的GRPO算法。
二是针对使用混合架构进行强化学习扩展时存在的挑战,如架构的训练内核和推理内核之间存在精度不匹配,阻碍了强化学习期间的奖励增长,为此开发了针对性的解决方案。
此外,为防止过于激进扩展训练长度可能导致训练过程中突然发生梯度爆炸(模型失控),MiniMax通过四个阶段采用更平滑的上下文长度进行扩展,从32K开始,最终将上下文扩展到1M。
“得益于这些技术创新,我们最终强化训练过程非常高效,超出预期。”MiniMax论文介绍,M1在整个强化学习阶段只用到512块H800三周的时间,租赁成本只有53.74万美金(约合人民币380万),“这比一开始的预期少了一个数量级”。
和豆包采取相同价格策略,MiniMax还有更多更新
目前,MiniMax-M1已经对外开源,并在MiniMax APP和Web端免费升级。在API价格方面,MiniMax和字节最新更新的豆包1.6同样采用了“区间定价”策略。

在0-32k输入长度和32k-128k输入长度下,M1的价格相比未按区间计价的DeepSeek-R1(输入4元/百万token,输出16元/百万token)更有性价比,而对于最长的128k-1M的输入长度,DeepSeek模型则不支持。
同时,M1划分的三个区间价格与豆包1.6对应区间价格也相同,但豆包1.6最后一个区间的最长长度为256k。可以说,M1成为和豆包一样的大模型价格杀手,这也正是得益于其相对高效的训练和推理算力效率。
“性价比新王”、“又一次卷到硅谷了”,不少开发者对M1评价到。
MiniMax认为,M1将在未来的智能体应用中具有独特优势。“我们预见这种高效架构在解决现实挑战方面具有巨大潜力,包括自动化工作流程、科学研究等。”
“未来智能体需要数十到数百个回合进行推理,同时整合来自不同来源的长上下文信息,我们未来将进一步朝着这一目标前进。”MiniMax表示。
搜狐科技了解到,目前MiniMax正在面向海外内测智能体应用,主打代码、多模态等能力,同时支持调用多款MCP工具。
值得注意的是,M1是MiniMax此次为期5天发布周的第一弹,后续该公司将官宣推出智能体,并在海螺AI视频、音乐等模型和产品层面带来更多更新。
此前,MiniMax进行了品牌调整,原有的对话类应用海螺AI更名为MiniMax,包括国内及国际市场,海螺品牌将专指AI视频海螺视频,从而在产品品牌上进行了明确划分。
在DeepSeek冲击下,昔日“AI六小龙”受到市场质疑,也做出了不同选择,零一万物和百川智能放弃大模型训练,其它几家则在不同层面谋求突围。
MiniMax显然还在坚持大模型训练,并通过卷成本、卷效率,试图向DeepSeek等领先模型发起挑战,有望为其在未来的大模型格局竞争中获取更多胜算。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






